Web based School
Red Hat Linux rhl10



10
Using bash
This chapter looks at the shells in a little more detail. You'll start with bash (Bourne Again Shell), the default shell used by Linux and the most popular shell for new users. In this chapter you will learn
- What a shell is
- The most common shells used in Linux
- Command-line completion and wildcards
- Command history and aliases
- Redirection and pipes
- Changing prompts
- Job control
- How to customize your bash shell
You will also look at the most commonly used bash commands and the environment variables bash uses. By the end of this chapter, you should be able to work faster and more efficiently with bash.
Shells in a Nutshell
What is a shell, anyway? It seems to be a word used all the time in Linux, but the exact meaning is vague for many new users (and some veterans). This section explains exactly what a shell program is and why it is so important when using Linux.
What Is a Shell?
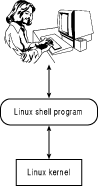
The shell is a program used to interface between you (the user) and Linux (or, more accurately, between you and the Linux kernel). Figure 10.1 illustrates the relationship between the user, the shell, and the Linux kernel. Every command you type at a
prompt on your screen is interpreted by the shell, then passed to the Linux kernel.
Figure 10.1. The relationship between the user and the shell.
{kind=link}
If you are familiar with MS-DOS, you will recognize this relationship as almost identical to the relationship between a DOS user and the COMMAND.COM program. The only real difference is that in the DOS world, no distinction is made between the COMMAND.COM program and DOS (or to be more accurate, the DOS kernel).
The shell is a command-language interpreter. It has its own set of built-in shell commands. The shell can also make use of all of the Linux utilities and application programs that are available on the system.
Whenever you enter a command it is interpreted by the Linux shell. For example, in earlier chapters when you were introduced to the Linux file- and directory-manipulation commands, all of the sample commands entered at the command prompt were
interpreted by whichever Linux shell you were using.
Some of the commands, such as the print working directory (pwd) command, are built into the Linux bash shell. Other commands, such as the copy command (cp) and the remove command (rm), are separate executable programs that exist in one of the
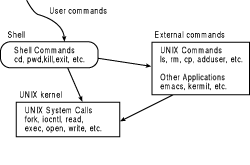
directories in the filesystem. As the user, you don't know (or probably care) if the command is built into the shell or is a separate program. Figure 10.2 shows how the shell performs this command interpretation.
Figure 10.2. Command interpretation by the shell.
{kind=link}
Figure 10.2 illustrates the steps that the shell takes to figure out what to do with user commands. It first checks to see if the command is one of its own built-in commands (like cd or pw. If the command is not one of these, the shell checks to see if
it is an application program. Application programs can be utility programs that are part of Linux, such as ls and rm, or they can be application programs that are either purchased commercially, such as xv, or available as public domain software, such as
ghostview.
The shell tries to find these application programs by looking in all of the directories that are in your search path. The path is a list of directories where executable programs can be found. If the command that was entered is not an internal shell
command and it is not an executable file in your path, an error message will be displayed.
As the last step in a successful command, the shell's internal commands and all of the application programs are eventually broken down into system calls and passed to the Linux kernel.
Another important aspect of the shell is that it contains a very powerful interpretive programming language. This language is similar in function to the MS-DOS interpreted language, but is much more powerful. The shell programming language supports most
of the programming constructs found in high-level languages, such as looping, functions, variables, and arrays.
The shell programming language is easy to learn, and once known it becomes a very powerful programming tool. Any command that can be typed at the command prompt can also be put into a executable shell program. This means that the shell language can be
used to simplify repetitive tasks. See Chapter 13, "Shell Programming," for more information on shell programming.
How the Shell Gets Started
Earlier in this chapter you learned that the shell is the main method by which a user interacts with the Linux kernel. But how does this program get initialized to do so? The shell is started after you successfully log into the system, and it continues
to be the main method of interaction between the user and the kernel until you log out.
Each user on your system has a default shell. The default shell for each user is specified in the system password file, called /etc/passwd. The system password file contains, among other things, each person's user ID, an encrypted copy of each user's
password, and the name of the program to run immediately after a user logs into the system. The program specified in the password file does not have to be one of the Linux shells, but it almost always is.
The Most Common Shells
Several different kinds of shells are available on Linux and UNIX systems. The most common are the Bourne shell (called sh), the C shell (csh), and the Korn shell (ksh). Each of these three shells has its own advantages and disadvantages.
The Bourne shell was written by Steven Bourne. It is the original UNIX shell and is available on every UNIX system in existence. The Bourne shell is considered to be very good for UNIX shell programming, but it does not handle user interaction as well
as some of the other shells available.
The C shell, written by Bill Joy, is much more responsive to user interaction. It supports features such as command-line completion that are not in the Bourne shell. The C shell's programming interface is thought by many not to be as good as that of the
Bourne shell, but it is used by many C programmers because the syntax of its programming language is similar to that of the C language. This is also why it is named the C shell.
The Korn shell (ksh) was written by Dave Korn. He took the best features of both the C shell and the Bourne shell and combined them into one that is completely compatible with the Bourne shell. ksh is efficient and has both a good interactive interface
and a good programming interface.
There are many quality reference guides about the Bourne, C, and Korn shells. If you want to use these shells instead of the three shells discussed in this and the next two chapters, you may want to find a good reference guide on the particular shell you prefer. Because the shells included with Linux are used by most people, we will concentrate on those.
In addition to these shells, many other shell programs took the basic features from one or more of the existing shells and combined them into a new version. The three newer shells that will be discussed in this guide are tcsh (an extension of csh), the
Bourne Again Shell (bash, an extension of sh), and the Public Domain Korn Shell (pdksh, an extension of ksh). bash is the default shell on most Linux systems.
The Bourne Again Shell
The Bourne Again Shell (bash), as its name implies, is an extension of the Bourne shell. bash is fully backward-compatible with the Bourne shell, but contains many enhancements and extra features that are not present in the Bourne shell. bash also
contains many of the best features that exist in the C and Korn shells. bash has a very flexible and powerful programming interface, as well as a user-friendly command interface.
Why use bash instead of sh? The biggest drawback of the Bourne shell is the way that it handles user input. Typing commands into the Bourne shell can often be very tedious, especially if you are using it on a regular basis and typing in a large number
of commands. bash provides several features that make entering commands much easier.
Command-Line Completion
Often when you enter commands into bash (or any other shell), the complete text of the command is not necessary in order for the shell to be able to determine what you want it to do. For example, assume that the current working directory contains the
following files and subdirectories:
News/ bin/ games/ mail/ samplefile test/
If you want to change directories from the current working directory to the test subdirectory, you would enter the command
cd test
Although this command will work, bash enables you to accomplish the same thing in a slightly different way. Since test is the only file in the directory that begins with the letter t, bash should be able to figure out what you want to do after you type
in the letter t alone:
cd t
After the letter has been typed, the only thing that you could be referring to is the test subdirectory. To get bash to finish the command for you, press the Tab key:
cd t<tab>
When you do this, bash finishes the command for you and displays it on the screen. The command doesn't actually execute until you press the Enter key to verify that the command bash came up with is the command that you really intended.
For short commands like this, you might not see very much value in making use of command-line completion. Using this feature may even slow you down when typing short commands. After you get used to using command-line completion, though, and when the
commands that you are entering get a little longer, you will wonder how anyone lived without this feature.
So what happens if more than one file in the directory begins with the letter t? It would seem that this would cause a problem if you wanted to use command-line completion. Let's see what happens when you have the following directory contents:
News/ bin/ mail/ samplefile test/ tools/ working/
Now you have two files in the directory that start with the letter t. Assuming that you still want to cd into the test subdirectory, how do you do it using command-line completion? If you type cd t<tab> as you did before, bash will not know which
subdirectory you want to change to because the information you have given is not unique.
If you try to do this, bash will beep to notify you that it does not have enough information to complete the command. After beeping, bash will leave the command on the screen as it was entered. This enables you to enter more information without retyping
what was already typed. In this case, you only need to enter an e and press the Tab key again. This will give bash enough information to complete the command on the command line for you to verify:
cd test
If instead you decided that you want to cd into the tools subdirectory, you could have typed
cd to<tab>
This would also give bash enough information to complete the command.
Whenever you press the Tab key while typing a command, bash will try to complete the command for you. If it can't complete the command, it will fill in as much as it can and then beep, notifying you that it needs more information. You can then enter
more characters and press the Tab key again, repeating this process until bash returns the desired command.
Wildcards
Another way that bash makes typing commands easier is by enabling users to use wildcards in their commands. The bash shell supports three kinds of wildcards:
* matches any character and any number of characters.
? matches any single character.
[...] matches any single character contained within the brackets.
The * wildcard can be used in a manner similar to command-line completion. For example, assume the current directory contains the following files:
News/ bin/ games/ mail/ samplefile test/
If you want to cd into the test directory, you could type cd test, or you could use command-line completion:
cd t<tab>
This causes bash to complete the command for you. Now there is a third way to do the same thing. Because only one file begins with the letter t, you could also change to the directory by using the * wildcard. You could enter the following command:
cd t*
The * matches any character and any number of characters, so the shell will replace the t* with test (the only file in the directory that matches the wildcard pattern).
This will work reliably only if there is one file in the directory that starts with the letter t. If more than one file in the directory starts with the letter t, the shell will try to replace t* with the list of filenames in the directory that match
the wildcard pattern and the cd command will cd into the first directory in this list. This will end up being the file that comes first alphabetically, and may or may not be the intended file.
A more practical situation in which to use the * wildcard is when you want to execute the same command on multiple files that have similar filenames. For example, assume the current directory contains the following files:
ch1.doc ch2.doc ch3.doc chimp config mail/ test/ tools/
If you wanted to print all of the files that have a .doc extension, you could do so easily by entering the following command:
lpr *.doc
In this case, bash will replace *.doc with the names of all of the files in the directory that match that wildcard pattern. After bash performed this substitution, the command that would be processed would be:
lpr ch1.doc ch2.doc ch3.doc
The lpr command would be invoked with the arguments of ch1.doc, ch2.doc, and ch3.doc.
Given the directory contents used in the previous example, there are several ways to print all of the files that have a .doc extension. All of the following commands would also work:
lpr *doc
lpr *oc
lpr *c
The ? wildcard functions in an identical way to the * wildcard except that the ? wildcard only matches a single character. Using the same directory contents shown in the previous example, the ? wildcard could be used to print all of the files with the
.doc extension by entering the following command:
lpr ch?.doc
The [...] wildcard enables you to specify certain characters or ranges of characters to match. To print all of the files in the example that have the .doc extension using the [...] wildcard, you would enter one of the following two commands:
lpr ch[123].doc
Using a command to specify a range of characters, you would enter
lpr ch[1-3].doc
Command History
bash also supports command history. This means that bash keeps track of a certain number of previous commands that have been entered into the shell. The number of commands is given by a shell variable called HISTSIZE. For more information on HISTSIZE,
see the section "bash Variables" later in this chapter.
bash stores the text of the previous commands in a history list. When you log into your account, the history list is initialized from a history file. The filename of the history file can be set using the HISTFILE bash variable. The default filename for
the history file is .bash_history. This file is usually located in your home directory. (Notice that the file begins with a period. This means that the file is hidden and will only appear in a directory listing if you use the -a or -A option of the ls
command.).
Just storing previous commands into a history file is not all that useful, so bash provides several ways of recalling them. The simplest way of using the history list is with the up- and down-arrow keys, which scroll through the commands that have been
previously entered.
Pressing the up-arrow key will cause the last command that was entered to appear on the command line. Pressing the up-arrow key again will put the command previous to that one on the command line, and so on. If you move up in the command buffer past the
command that you wanted, you can also move down the history list a command at a time by pressing the down-arrow key. (This is the same process used by the DOS doskey utility.)
The command displayed on the command line through the history list can be edited, if needed. bash supports a complex set of editing capabilities that are beyond the scope of this guide, but there are simple ways of editing the command line for small and
easy changes. You can use the left and right arrow keys to move along the command line. You can insert text at any point in the command line, and can also delete text by using the Backspace or Delete key. Most users should find these simple editing
commands sufficient.
The complex set of editing commands that bash offers are similar to the commands used in the emacs and vi text editors.
Another method of using the history file is to display and edit the list using the history and fc (fix command) commands built into bash. The history command can be invoked using two different methods. The first method uses the command
history [n]
When the history command is used with no options, the entire contents of the history list are displayed. The list that is displayed on-screen might resemble the following sample list:
1 mkdir /usr/games/pool 2 cp XpoolTable-1.2.linux.tar.z /usr/games/pool 3 cd /usr/games/pool/ 4 ls 5 gunzip XpoolTable-1.2.linux.tar.z 6 tar -xf XpoolTable-1.2.linux.tar 7 ls 8 cd Xpool 9 ls 10 xinit 11 exit 12 which zip 13 zip 14 more readme 15 vi readme 16 exit
Using the n with the history command causes the only last n lines in the history list to be shown. So, for example, history 5 shows only the last five commands.
The second method of invoking the history command is used to modify the contents of the history file, or the history list. The command has the following command-line syntax:
history [-r|w|a|n] [filename]
In this form, the -r option tells the history command to read the contents of the history file and use them as the current history list. The -w option will cause the history command to write the current history list to the history file (overwriting what
is currently in the file). The -a option appends the current history list to the end of the history file. The -n option causes the lines that are in the history file to be read into the current history list.
All of the options for the second form of the history command can use the filename option as the name of the history file. If no filename is specified, the history command will use the value of the HISTFILE shell variable.
The fc command can be used in two different ways to edit the command history. In the first way, the fc command would be entered using the following command-line syntax:
fc [-e editor_name] [-n] [-l] [-r] [first] [last]
where all options given in braces are optional. The -e editor name option is used to specify the text editor to be used for editing the commands. The first and last options are used to select a range of commands to take out of the history list. first
and last can refer either to the number of a command in the history list or to a string that fc will try to find in the history list.
The -n option is used to suppress command numbers when listing the history commands. The -r option lists the matched commands in reverse order. The -l command lists the matched commands to the screen. In all cases except when the -l command option is
used, the matching commands will be loaded into a text editor.
The text editor used by fc is found by taking the value of editor name if the -e editor name option is used. If this option was not used, fc uses the editor specified by the variable FCEDIT. If this variable does not exist, fc will use the value of the EDITOR variable. Finally, if none of these variables exists, the editor that will be chosen is vi, by default.
Aliases
Another way that bash makes life easier for you is by supporting command aliases. Command aliases are commands that the user can specify. Alias commands are usually abbreviations of other commands, designed to save keystrokes.
For example, if you are entering the following command on a regular basis, you might be inclined to create an alias for it to save yourself some typing:
cd /usr/X11R6/lib/X11/config
Instead of typing this command every time you wanted to go to the sample-configs directory, you could create an alias called goconfig that would cause the longer command to be executed. To set up an alias like this you must use the bash alias command.
To create the goconfig alias, enter the following command at the bash prompt:
alias goconfig='cd /usr/X11R6/lib/X11/configs
Now, until you exit from bash, the goconfig command will cause the original, longer command to be executed as if you had just typed it.
If you decide after you have entered an alias that you did not need it, you can use the bash unalias command to delete the alias:
unalias goconfig
There are a number of useful aliases that most users find helpful. These can be written in a file that you execute when you log in, to save you from typing them each time. Some aliases that you might want to define are the following:
- alias ll='ls -l'
- alias log='logout'
- alias ls='ls -F'
If you are a DOS user and are used to using DOS file commands, you can use the alias command to define the following aliases so that Linux behaves like DOS:
- alias dir='ls'
- alias copy='cp'
- alias rename='mv'
- alias md='mkdir'
- alias rd='rmdir'
When defining aliases, you can't include spaces on either side of the equal sign, or the shell can't properly determine what you want to do. Quotation marks are necessary only if the command within them contains spaces or other special characters.
If you enter the alias command without any arguments, it will display all of the aliases that are already defined on-screen. The following listing illustrates a sample output from the alias command:
alias dir='ls' alias ll='ls -l' alias ls='ls -F' alias md='mkdir' alias net='term < /dev/modem > /dev/modem 2> /dev/null&' alias rd='rmdir'
Input Redirection
Input redirection is used to change the source of input for a command. When a command is entered in bash, the command is expecting some kind of input in order to do its job. Some of the simpler commands must get all of the information that they need
passed to them on the command line. For example, the rm command requires arguments on the command line. You must tell rm the files that you want it to delete on the command line, or it will issue a prompt telling you to enter rm -h for help.
Other commands require more elaborate input than a simple directory name. The input for these commands can be found in a file. For example, the wc (word count) command counts the number of characters, words, and lines in the input that was given to it.
If you just type wc <enter> at the command line, wc waits for you to tell it what it should be counting. There will be a prompt on the command line asking for more information, but because the prompt is sometimes not easily identifiable, it will not
necessarily be obvious to you what is happening. (It might actually appear as though bash has died, because it is just sitting there. Everything that you type shows up on-screen, but nothing else appears to be happening.)
What is actually occurring is that the wc command is collecting input for itself. If you press Ctrl-D, the results of the wc command will be written to the screen. If you enter the wc command with a filename as an argument, as shown in the following
example, wc will return the number of characters, words, and lines that are contained in that file:
wc test 11 2 1
Another way to pass the contents of the test file to wc is to redirect the input of the wc command from the terminal to the test file. This will result in the same output. The < symbol is used by bash to mean "redirect the input to the current
command from the specified file." So, redirecting wc's input from the terminal to the test file can be done by entering the following command:
wc < test 11 2 1
Input redirection is not used all that often because most commands that require input from a file have the option to specify a filename on the command line. There are times, however, when you will come across a program that will not accept a filename as
an input parameter, and yet the input that you want to give exists in a file. Whenever this situation occurs, you can use input redirection to get around the problem.
Output Redirection
Output redirection is more commonly used than input redirection. Output redirection enables you to redirect the output from a command into a file, as opposed to having the output displayed on-screen.
There are many situations in which this can be useful. For example, if the output of a command is quite large and will not fit on the screen, you might want to redirect it to a file so that you can view it later using a text editor. There also may be
cases where you want to keep the output of a command to show to someone else, or so you can print the results. Finally, output redirection is also useful if you want to use the output from one command as input for another. (There is an easier way to use
the output of one command as input to a second command. This is shown in the "Pipelines" section in this chapter.)
Output redirection is done in much the same way as input redirection. Instead of using the < symbol, the > symbol is used.
The best way to remember which symbol is input or output redirection is to think of the < as a funnel that is funneling input into the command (because the command receiving the input will be on the left-hand side of the <) and the > as a funnel that is funneling the output from the command into a file.
As an example of output redirection, you can redirect the output of the ls command into a file named directory.out using the following command:
ls > directory.out
Pipelines
Pipelines are a way to string together a series of commands. This means that the output from the first command in the pipeline is used as the input to the second command in the pipeline. The output from the second command in the pipeline is used as
input to the third command in the pipeline, and so on. The output from the last command in the pipeline is the output that you will actually see displayed on-screen (or put in a file if output redirection was specified on the command line).
You can tell bash to create a pipeline by typing two or more commands separated by the vertical bar or pipe character, |. The following example illustrates the use of a pipeline:
cat sample.text | grep "High" | wc -l
This pipeline would take the output from the cat command (which lists the contents of a file) and send it into the grep command. The grep command searches for each occurrence of the word High in its input. The grep command's output would then consist of
each line in the file that contained the word High. This output is then sent to the wc command. The wc command with the -l option prints the number of lines contained in its input.
To show the results on a real file, suppose the contents of sample.text was
Things to do today: Low: Go grocery shopping High: Return movie High: Clear level 3 in Alien vs. Predator Medium: Pick up clothes from dry cleaner
The pipeline would return the result 2, indicating that you had two things of high importance to complete today:
cat sample.text | grep "High" | wc -l 2
Prompts
bash has two levels of user prompt. The first level is what you see when bash is waiting for a command to be typed. (This is what you normally see when you are working with bash.)
The default first-level prompt is the $ character. If you do not like the $ character as the prompt, or you would prefer to customize your prompt, you can do so by setting the value of the PS1 bash variable. For example:
PS1="Please enter a command"
sets the bash shell prompt to the specified string.
The second level of prompt is displayed when bash is expecting more input from you in order to complete a command. The default for the second level prompt is >. If you want to change the second-level prompt, you can set the value of the PS2 variable,
as in
PS2="I need more information"
In addition to displaying static character strings in the command prompts (as in the two preced-ing examples), you can also use some predefined special characters. These special characters place things such as the current time into the prompt. Table
10.1 lists the most commonly used special-character codes.
| Character | Meaning |
| \! | Displays the history number of this command. |
| \# | Displays the command number of the current command. |
| \$ | Displays a $ in the prompt unless the user is root. When the user is root, it displays a #. |
| \\ | Displays a backslash. |
| \d | Displays the current date. |
| \h | Displays the host name of the computer on which the shell is running. |
| \n | Prints a newline character. This will cause the prompt to span more than one line. |
| \nnn | Displays the character that corresponds to the octal value of the number nnn. |
| \s | The name of the shell that is running. |
| \t | Displays the current time. |
| \u | Displays the username of the current user. |
| \W | Displays the base name of the current working directory. |
| \w | Displays the current working directory. |
These special characters can be combined into several useful prompts to provide you with information about where you are. (They can be combined in very grotesque ways, too!) Several examples of setting the PS1 prompt are:
PS1="\t"
This would cause the prompt to have the following appearance (there would not be a space after the prompt):
02:16:15
The prompt string
PS1=\t
would cause the prompt to have the following appearance:
t
This shows the importance of including the character sequence in quotation marks. The prompt string
PS1="\t\\ "
will cause the prompt to look like this:
02:16:30\
In this case, there would be a space following the prompt because there was a space within the quotation marks.
Job Control
Job control refers to the ability to control the execution behavior of a currently running process. Specifically, you can suspend a running process and cause it to resume running at a later time. bash keeps track of all of the processes that it started
(as a result of user input), and you can suspend a running process or restart a suspended one at any time during the life of that process.
Pressing Ctrl-Z suspends a running process. The bg command restarts a suspended process in the background, whereas the fg command restarts a process in the foreground.
These commands are most often used when a user wants to run a command in the background but by accident starts it in the foreground. When a command is started in the foreground, it locks the shell from any further user interaction until the command
completes execution. This is usually no problem because most commands only take a few seconds to execute. If the command you are running is going to take a long time, though, you would typically start the command in the background so that you could
continue to use bash to enter other commands in the foreground.
For example, if you started the command find / -name "test" > find.out (which will scan the entire filesystem for files named test and store the results in a file called find.out) in the foreground, your shell may be tied up for many
seconds or even minutes, depending on the size of the filesystem and the number of users on the system. If you had issued this command and wanted to continue executing in the background so you could use the system again, you would enter the following:
control-z bg
This would first suspend the find command, then restart it in the background. The find command would continue to execute, and you would have bash back again.
Customizing bash
Many ways of customizing bash have already been described in this chapter. Until now, the changes that you made affected only the current bash session. As soon as you quit, all of the customizations that you made will be lost. You can make the
customizations more permanent by storing them in a bash initialization file.
You can put any commands that you want to be executed each time bash is started into this initialization file. Commands that are typically found in this file are alias commands and variable initializations.
The bash initialization file is named profile. Each user who uses bash has a .profile file in his home directory. This file is read by bash each time it starts, and all of the commands contained within it are executed.
The following code shows the default .profile file. This file is located in the /etc directory and is read when you start bash. If you want to add your own customizations to bash, you must copy this file into your home directory (if it is not already
there) and call it .profile.
Some setup programs make a copy of the .profile file in your home directory for you automatically when they create your login. However, not all routines do this, so you should check your home directory first. Remember that all files starting with a period are hidden and can only be displayed with the ls -A or ls -a command.
# commands common to all logins export OPENWINHOME=/usr/openwin export MINICOM="-c on" export MANPATH=/usr/local/man:/usr/man/preformat:/usr/man:/X11/man:/usr/openwin/man export HOSTNAME="'cat /etc/HOSTNAME'" PATH="$PATH:/usr/X11/bin:$OPENWINHOME/bin:/usr/games:." LESS=-MM # I had problems using 'eval test' instead of 'TERM=', but you might want to
# try it anyway. I think with the right /etc/termcap it would work great.
# eval 'tset -sQ "$TERM"'if [ "$TERM" = "" -o "$TERM" = "unknown"]; then TERM=linux fi #PS1=''hostname':'pwd'# ' if [ "$SHELL" = "/bin/pdksh" -o "$SHELL" = "/bin/ksh" ]; then PS1="! $" elif [ "$SHELL" = "/bin/zsh" ]; then PS1="%m:%~%# " elif [ "$SHELL" = "/bin/ash" ]; then PS1="$ " else PS1='\h:\w\$ ' fi PS2='> ' ignoreeof=10 export PATH DISPLAY LESS TERM PS1 PS2 ignoreeof umask 022 # set up the color-ls environment variables: if [ "$SHELL" = "/bin/zsh" l; then eval 'dircolors -z' elif [ "$SHELL" = "/bin/ash" l; then eval 'dircolors -s' else eval 'dircolors -b' fi echo fortune echo export TAPE="/dev/nftape"
bash Command Summary
Here are some of the most useful commands built into the bash shell:
alias: Used to set bash aliases (command nicknames that can be defined by the user).
bg: Background command. Forces a suspended process to continue to execute in the background.
cd: Change working directory. This command changes the current working directory to the directory specified as an argument.
exit: Terminates the shell.
export: Causes the value of a variable to be made visible to all subprocesses that belong to the current shell.
fc: Fix command. Used to edit the commands in the current history list.
fg: Foreground command. Forces a suspended process to continue to execute in the foreground.
help: Displays help information for bash built-in commands.
history: Brings up a list of the last n commands that were entered at the command prompt, where n is a configurable variable specifying the number of commands to remember.
kill: Used to terminate another process.
pwd: Print working directory. Prints the directory in which the user is currently working.
unalias: Used to remove aliases that have been defined using the alias command.
bash has many more commands than are listed here, but these are the most frequently used ones. To see the other commands bash offers and for more details of the commands listed, refer to the bash man page (type man bash).
bash Variables
Here are some of the most useful bash variables, including the variable name and a brief description:
EDITOR, FCEDIT: The default editor for the fc bash command.
HISTFILE: The file used to store the command history.
HISTSIZE: The size of the history list.
HOME: The HOME directory of the current user
OLDPWD: The previous working directory (the one that was current before the current directory was entered).
PATH: The search path that bash uses when looking for executable files
PS1: The first-level prompt that is displayed on the command line
PS2: The second-level prompt that is displayed when a command is expecting more input
PWD: The current working directory
SECONDS: The number of seconds that have elapsed since the current bash session was started
bash has many more variables than are listed here, but the most commonly used ones are shown. To find out what other variables bash offers, call the man page with the command man bash.
Summary
In this chapter you looked at some of the useful features of the Bourne Again Shell, bash. You have seen how command completion, aliasing, and job control can all combine to make you more productive and efficient when working with bash.
In the next chapter you will look at another popular Linux shell, the Public Domain Korn Shell (pdksh). It offers many useful features, too, providing you with a choice of shells.

Popular Tutorials
-
 MS Access
1109
MS Access
1109
-
 C++
1222
C++
1222
-
 HTML
584
HTML
584
-
 JavaScript
616
JavaScript
616
-
 Vbscript
873
Vbscript
873
-
 Oracle
473
Oracle
473
-
 VC++
875
VC++
875
-
 SQL
2959
SQL
2959
-
 XML
514
XML
514
-
 Java
814
Java
814
-
 Perl
455
Perl
455
-
 Linux
451
Linux
451