Web based School
Red Hat Linux rhl48



48
Configuring a WAIS Site
WAIS (Wide Area Information Service) is a menu-based tool that enables users to search for keywords in a database of documents available on your system and show the results. WAIS was developed by Thinking Machines but spun off to a separate company
called WAIS Inc., when it became immensely popular and was then purchased by AOL Productions. A free version of WAIS was made available to the Clearinghouse for Networking Information Discovery and Retrieval (CNIDR) as freeWAIS, which is the version most
often found on Linux systems.
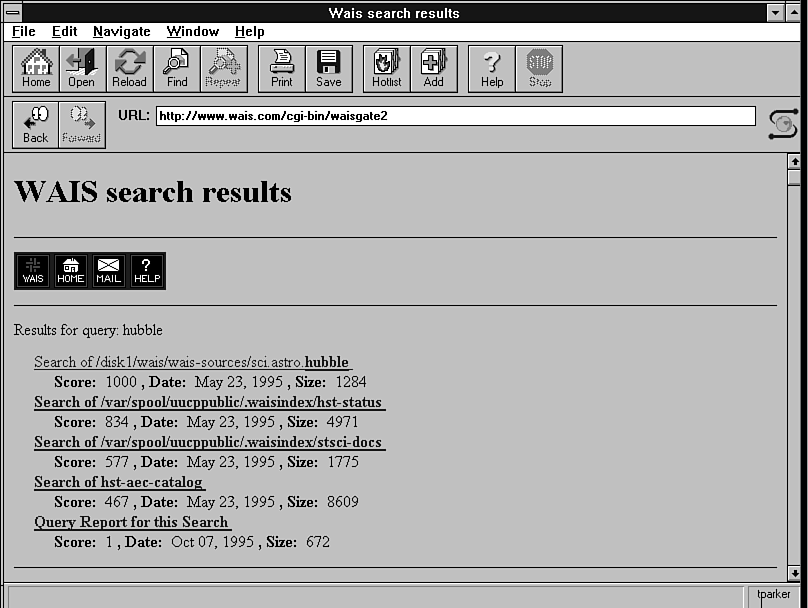
WAIS lets a user enter some keywords or phrases, and then searches a database for those terms. A typical WAIS search screen is shown in Figure 48.1. (This screen is from the primary WAIS server at http://www.wais.com.
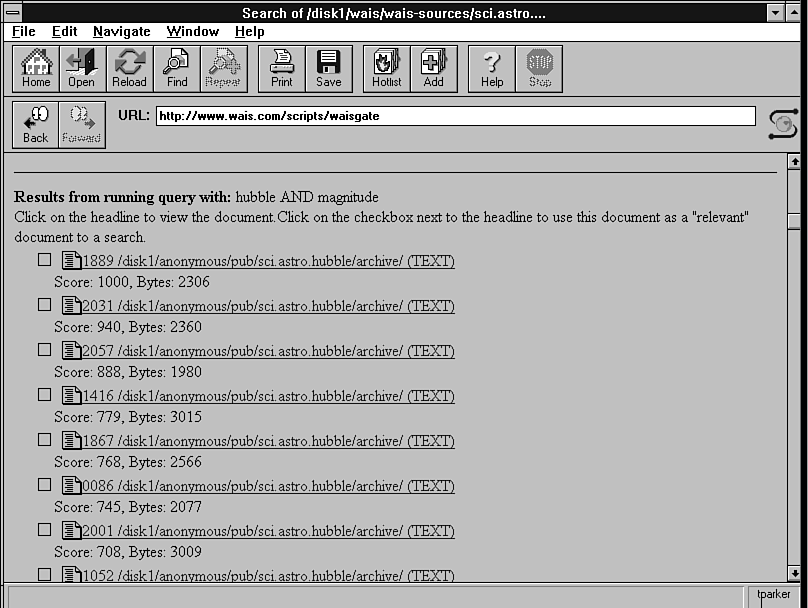
This server is a good place to look for examples of how WAIS can be used.) In this example, we searched for the keywords hubble and magnitude (WAIS usually ignores case). After searching all the database indexes it knows about, WAIS shows its results, as
shown in Figure 48.2.
Figure 48.1. You can enter complex or simple search criteria on a WAIS search line.
Figure 48.2. WAIS displays the search results with a score.
The display generated by WAIS, often displayed in a WWW browser or a WAIS browser as in these figures, lists each match along with its score from 0 to 1000, indicating the manner in which the keywords match the index (the higher numbers are better
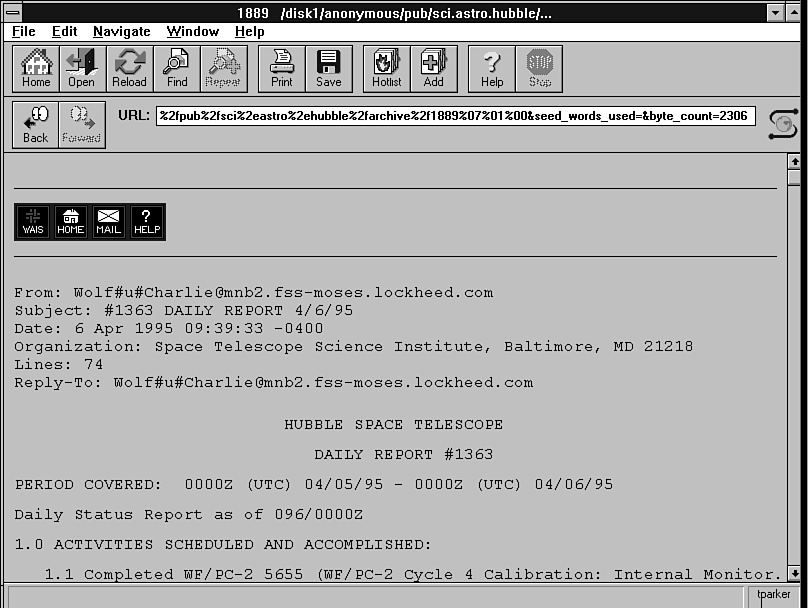
matches). Users can then refine the list, expand it, or examine documents listed. In Figure 48.3, one of the documents listed in the search results is displayed in the WWW browser window. WAIS can handle many file formats, including text and documents,
audio, JPEG and GIF files, and binaries.
Figure 48.3. Selecting any entry on the WAIS search results lets you see the file.
The version of WAIS used commonly with Linux is called freeWAIS. This chapter looks at how you can set up a freeWAIS server on your Linux machine. WAIS is a useful service to provide if you deal with a considerable amount of information that you want to
make generally available. This could be product information, details about a hobby, or practically any other type of data. All you have to want to do is make it available to others, either on your local area network or to the Internet as a whole.
The freeWAIS package has three parts to it: an indexer, a WAIS server, and a client. The indexer handles database information and generates an index that contains keywords and a table indicating the words' occurrences. The server component does the
matching between a user's requests and the indexed files. The client is the user's vehicle to access WAIS, and is usually a WAIS or WWW browser. WWW browsers usually have an advantage over WAIS browsers in that the latter cannot display HTML documents.
A follow-up backwards-compatible WAIS system is currently available in a beta version called ZDIST. ZDIST's behavior will be much like freeWAIS, with any changes noted in the documentation. ZDIST adds some new features and is a little smaller and faster
than freeWAIS. Because of the unstable beta nature of ZDIST, we'll concentrate on freeWAIS here.
Compiling and Installing freeWAIS
The freeWAIS software is often included in a complete Linux distribution CD-ROM but is also readily available from many FTP and BBS sites. Alternatively, it can be obtained by anonymous FTP from the CNIDR site as ftp.cnidr.org. The freeWAIS system resides in the directory /pub/NDIR.tools/freewais/freeWAIS-X.X.tar.Z where X.X is the latest version number. The CNIDR site has many binaries available for different machines, as well as
generic source code that can be tailored to many different systems.
One of the files in the distribution software, which should be placed in the destination directory, is the Makefile used to create the program. If you are compiling the freeWAIS source yourself, examine the Makefile to ensure the variables are set
correctly. Most are fine by default, pointing to standard Linux utilities. The following lists some of the exceptions that you may have to tweak:
| CC | The name of the C compiler you use (usually cc or gcc). |
| CURSELIB | Set to the current version of the curses library on your system. |
| TOP | The full path to the freeWAIS source directory. |
The CFLAGS options let you specify compiler flags when the freeWAIS source is compiled. Many options are supported, all explained in the documentation files that accompany the source. Most of the flag settings can be left as their default values
in Linux systems. A few of the specific flags you may want to alter are worth mentioning, though. The most useful are the indexer flags, two of which are potentially useful:
| -DBIO | Used to allow indexing on biological symbols and terms. Use only if your site deals with biological documents. |
| -DBOOLEANS | Enables you to use Booleans as AND and NOT. This flag can be handy for extending the power of searches. |
The -DBOOLEANS flag handles logical searches. For example, if you are looking for the keywords "green leaf," WAIS by default searches for the words green and leaf separately and judges matches on the two words independently. With the
-DBOOLEANS flag set, the two words can be ANDed together so a match has to be with the two-word term "green leaf."
A couple of other flags that may be useful for freeWAIS sites deal with the behavior of the system as a whole:
| -DBIGINDEX | Should be set when there are many (thousands) of documents to index. |
| -DLITERAL | Allows a literal search for a string, as opposed to using partial hits on the string's component words. |
| -DPARTIALWORD | Allows searches with asterisks as wildcards (such as auto*). |
| -DRELEVANCE_FEEDBACK | Set to ON, enables clients to use previous search results as search criteria for a new search. This is a useful option. |
A number of directories are included in the distribution software, most of which are of obvious intent (bin for binaries, man for man pages, and so on). The directories used by freeWAIS in its default configuration are as follows:
| bin | Binaries |
| config.c | C source code for configuration |
| doc | Doc files, help files, and FAQs |
| include | Header files used by the compiler |
| lib | Library files |
| man | Man pages |
| Src free | WAIS source code |
| Wais-Sources | Directory of Internet servers |
| Wais-Test | Sample indexer and service scripts |
Once you have fine-tuned the configuration file information, you can compile the freeWAIS source with the make command:
make linux
By default, the make utility compiles two clients called swais and waisq. If you want to compile an X version of WAIS called xwais (useful if you want to allow access from X terminals or consoles), uncomment the line in the Makefile that ends with
makex.
Setting Up freeWAIS
When you have the compiled freeWAIS components installed and configured properly, you can begin setting up the WAIS index files to documents available on your system. This is usually done by creating an index directory with the default name of wsindex.
The directory usually resides just under the root of the file system (/wsindex) but many administrators like to keep it in a reserved area for the WAIS software (such as /usr/wais/wsindex). If the index files are difficult to locate, users may have
problems when they try to find them.
The wais-test directory created when you installed freeWAIS contains a script called test.waisindex that creates four WAIS index files automatically for you. These are used to test the WAIS installation for proper functionality, as well as to show you
how you can use the different search and index capabilities of freeWAIS. The following are the four index files:
| test-BOOL | Index of three example documents using the Boolean capabilities and synonyms |
| test-Comp | Index demonstrating compressed source file handling |
| test-Docs | Index of files in the doc directory showing recursive directory search |
| test-Multi | Index of GIF images and multi-document capabilities |
Only graphically based (usually X-based) browsers can handle the Multi document formats, although any type of browser should be able to handle the other three index formats.
Once you have verified that the indexing system works properly and all the components of freeWAIS are properly installed, you need to build an index file for the documents available on your system. Do this with the waisindex command. The waisindex
command enables you to index files two ways using the -t option, followed by one of these keywords:
| one_line | Index each line of a document so a match can show the exact line the match occurred in. |
| text | Index so a match shows the entire document with no indication of the exact line the match occurred in. This is the default option. |
The waisindex command takes arguments for the name of the destination index file (-d followed by the filename), and the directory or files to be indexed. For example, to index a directory called /usr/sales/sales_lit into a destination index file
called sales, using the one_line indexing approach, you would issue the command:
waisindex -d sales -t one_line /usr/sales/sales_lit
Because there is no path provided for the sales index file in this example, it would be stored in the current directory.
Once your WAIS server is running (see the section entitled "Starting freeWAIS"), you can test the indexes by using the waissearch command. For example, to look for the word "WAIS" in the index files, issue the command:
waissearch -p 210 -d index_file WAIS
where -p gives the port number (default value is 210), and -d is the path to the index file. If the search is successful (and you have something that matches) you will see messages about the number of records returned and the scores of each match. If
you see error messages or nothing, check the configuration information and the index files.
A final step you can take if you want your freeWAIS system to be accessible by Internet users is to issue the command:
waisindex -export -register Filenames
where Filenames is the name of the index. This will be registered with the Directory of Servers at cnidr.org and quake.think.com. These addresses are reached automatically with the -register option. Only do this step if you want all Internet users to
access your WAIS service. (We will look at the waisindex command in much more detail shortly.)
If you want to enable clients to connect to your freeWAIS system with a WWW browser (such as Mosaic or Netscape), you must issue the command:
waisindex -d WWW -T HTML -contents -export /usr/resources/*html
Replace the /usr/resources path with the path to your HTML files. This line allows WAIS clients to perform keyword searches on HTML documents, as well.
If you want, you can set WAIS to allow only certain domains to connect to it. This is done in the ir.h file, which has a line like this:
#define SERVSECURITYFILE "SERV_SEC"
You have to place a copy of an existing SERV_SEC file or one you create yourself in the same directory as the WAIS index files. If there is no SERV_SEC file accessible to WAIS, all domains are allowed access. (You can change the name of the file, of
course, as long as the entry in ir.h matches the filename with quotation marks around it.)
Each ASCII entry in the SERV_SEC file follows a strict format for defining the domains that are granted access to WAIS. The format of each line is:
domain [IP address]
Each line has the domain name of the host that you want to grant access to with its IP address as an optional add-on to the line. If the domain name and IP address do not match, it doesn't matter because WAIS allows access to a match of either name or
address. A sample SERV_SEC file looks likes this:
chatton.com roy.sailing.org bighost.bignet.com
Each of these three domain names can access WAIS, while any connection from a host without these domain names is refused.
The SERV_SEC file should be owned and accessible only by the user that the freeWAIS system is running as (it should not be run as root to avoid security problems), and the file should be modifiable only by root.
Similar to the SERVSECURITYFILE variable is DATASECURITYFILE, which controls access to the databases. There is a line in the ir.h file that looks like this:
#define DATASECURITYFILE "DATA_SEC"
where DATA_SEC is a file listing each database file and the domains that have access to it. The file should reside in the same directory as the index files. The format of the DATA_SEC file is:
database domain [IP address]
where database is the name of the database the permissions refer to, and domain and the optional IP address are the same as the SERV_SEC file. A sample DATA_SEC file looks like this:
primary chatton.com primary bignet.org primary roy.sailing.org sailing roy.sailing.org
In this example, three domains are granted access to a database called primary (note that primary is just a filename and has no special meaning), while one domain has specific access to the database called sailing as well as primary. If you want to
allow all hosts with access to the system (controlled by SERV_SEC) to access a particular database, you can use asterisks in the domain name and IP address fields. For example, the entries:
primary * * sailing roy.sailing.org
allow anyone with access to WAIS to use the primary database, with only one domain allowed access to the sailing database.
In both the SERV_SEC and DATA_SEC files, you have to be careful with the IP addresses to avoid inadvertently granting access to hosts you really don't want on your system. For example, if you specify the IP address 150.12 in your file, then any IP
addresses from 150.12 through 150.120, 151.121, and so on, are also granted access because they match the IP components. Specify IP addresses explicitly to avoid this problem.
Starting freeWAIS
As with the FTP services, you can set freeWAIS to start up when the system boots, by using the rc files from the command line at any time, or you can have the processes started by inetd when a service request arrives. If you want to start freeWAIS from
the command line, you need to specify a number of options. A sample startup command line looks like this:
waisserver -u username -p 210 -l 10 -d /usr/wais/wais_index
The -u option tells waisserver to run as the user username (which has to be a valid user in /etc/passwd, of course), the -p option tells waisserver what port to use (the default is 210, as shown in the /etc/services file), and the -d option shows the
default location of WAIS indexes. If you want to invoke logging of sessions to a file, use the -e option followed by the name of the logfile.
You should run waisserver as another user instead of root to prevent holes in the WAIS system from being exploited by a hacker. If the service is run as a standard user (such as wais), only the files that the user would have access to would be in
jeopardy.
If the port for waisserver is set to 210, the service corresponds to the Internet standards for access. If you set the value to another port, you can configure the system for local area access only. If the port number is less than 1023, the WAIS service
must be started and managed by root, but any port over 1023 can be handled by a normal user. If you intend to use port 210, you don't have to specify the number in the command line, although the -p option still must be used.
If you want to let inetd handle the waisserver startup, you need to ensure the file /etc/services has an entry for WAIS. The line in the /etc/services file looks like this:
z3950 210/tcp #WAIS
where 210 is the port number WAIS uses, and tcp is the protocol. After modifying or verifying the entry in /etc/services, you need to add a WAIS entry to the inetd.conf file to start up waisserver whenever a request is received on port 210 (or whatever
other port you are using). The entry looks like this:
z3950 stream tcp nowait root/usr/local/bin/waisserver/waisserver.d -u username -d /usr/wais/wais_index
where the options are the same as for the command line startup mentioned above. The daemon waisserver.d is used when starting up in inetd mode, instead of waisserver. Again you can use the -e option to log activity to a file.
Building Your WAIS Indexes
Once you have the freeWAIS server ready to run and everything seems to be working, it's time to provide some content for your WAIS system. Usually, documents are the primary source of information for WAIS, although you can index any type of file. The
key step to providing WAIS service is to build the WAIS index using the waisindex command. The waisindex command can be a bit obtuse at times, but a little practice and some trial-and-error fiddling will help you master its somewhat awkward behavior.
The waisindex program works by examining all the data in the files in which you want to create an index. From its examination, waisindex usually generates seven different index files (depending on the content and your commands). Each file holds a list
of unique words in the documents. The different index files are then combined into one large database, often called the "source" (or "WAIS source"). Whenever a client WAIS package submits a search, the search strings are compared to the
source, and the results displayed with accuracy analysis (the match score).
The use of waisindex enables a client search to proceed much more quickly because the keywords in the data files have already been extracted. However, the mass of data in the index files can be sizable, so allow plenty of disk space for a WAIS server to work with. (For a typical WAIS site, assume at least double the amount of room needed for the source files.)
WAIS Index Files
The freeWAIS index files are not usually readable by a system user (although one or two files can be read with some success). Usually, waisindex creates seven index files, although the number may vary depending on requirements. Each index file has a
specific file extension to show its purpose, based on a root name (specified on the waisindex command line, or defaulting to index). The index files and their purposes are as follows:
| index.doc | A document file that contains a table with the filename, a headline (title) from the file, the location of the first and last characters of an entry, the length of the document, the number of lines in the document, and the time and date the document was created. |
| index.dct | A dictionary file that contains a list of every unique word in the files cross-indexed to the inverted file. |
| index.fn | A filename file that contains a table with a list of the filenames, the date they were created in the index, and the type of file. |
| index.hl | A headline file that contains a table of all headlines (titles). The headline is displayed in the search output when a match occurs. |
| index.inv | Inverted files that contain a table associating every unique word in all the files with a pointer to the files themselves and the word's importance (determined by how close the word is to the start of the file, the number of times the word occurs in the document, and the percentage of times the word appears in the document). |
| index.src | A source description file that contains descriptions of the information indexed, including the host name and IP address, the port watched by |
| WAIS, the source filename, any cost information | for the service, the headline of the service, a description of the source, and the e-mail address of the administrator. The source description file is editable by ASCII editors. We will look at this file in a little more detail shortly. |
| index.status | A status file containing user-defined information. |
The source description file is a standard ASCII file that is read by waisindex at intervals to see if information has changed. If the changes are significant, waisindex updates its internal information. A sample source file looks like this:
(:source :version 2 :ip-address "147.120.0.10" :ip-name: "wizard.tpci.com" :tcp-port 210 :database-name "Linux stuff" :cost 0.00 :cost-unit: free :maintainer "wais_help@tpci.com" :subjects "Everything you need to know about Linux" :description "If you need to know something about Linux, it's here."
You should edit this file when you set up freeWAIS because the default descriptions are rather sparse and useless.
The waisindex Command
The waisindex command allows a number of options, some of which you have seen earlier in this chapter. The following list contains the primary waisindex options of interest to most users:
| -a | Appends data to an existing index file (used to update index files instead of regenerating them each time a new document is added). |
| -contents | Indexes the file contents (default action). |
| -d | Gives the filename root for index files (for example, -d /usr/wais/foo named all index files as /usr/wais/foo.xxx). |
| -e | Gives the name of the log file for error information (default is stderr—usually the console—although you can specify -s for /dev/null). |
| -export | Adds the host name and TCP port to descriptions for easier Internet access. |
| -l | Gives the level of log messages. Valid values are 0—no log, 1—log only high priority errors and warnings, 5—log medium priority errors and warnings, as well as index filename information, and 10—log every event. |
| -M | Links multiple types of files. |
| -mem | Limits memory usage during indexing (the higher the number specified, the faster the indexing process and the more memory used). |
| -nocontents | Prevents a file from being indexed (indexes only the document header and filename). |
| -nopairs | Instructs waisindex to ignore adjacent capitalized words from being indexed together. |
| -nopos | Ignores the location of keywords in a document when determining scores. |
| -pairs | Indexes adjacent capitalized words as a single entry. |
| -pos | Determines scores based on locations of keywords (proximity of keywords increases scores). |
| -r | Recursive subdirectory indexing. |
| -register | Registers your indexes with the WAIS Directory of Services. |
| -stdin | Uses a filename from the keyboard instead of a filename on the command line. |
| -stop | Indicates a file containing stopwords (words too common to be indexed), usually defined in src/ir/stoplist.c. |
| -t | Data file type indicator. |
| -T | Sets the type of data to whatever follows. |
The waisindex program has to be told the type of information in a file, otherwise it may not be able to generate an index properly. Many file types are currently defined with freeWAIS, and you can display them by entering the command:
waisindex
with no argument. Although many different types are supported by freeWAIS, only a few are really in common use. The most common file types supported by freeWAIS are the following:
| filename | Same as text, except the filename is used as the headline. |
| first_line | Same as text, except the first line in the file is used as the headline. |
| ftp | Contains FTP code that users can use to retrieve information from another machine. |
| GIF | GIF images, one image per file. The filename is used as the headline. |
| mail_or_rmail | Indexes the mbox mailbox contents as individual items. |
| mail_digest | Standard e-mail, indexed as individual messages. The subject field is the headline. |
| netnews | Standard Usenet news, each article a separate item. The subject field is the headline. |
| one_line | Indexes each sentence in a document separately. |
| PICT | PICT image, one image per file. The filename is used as the headline. |
| ps | A PostScript file with one document per file. |
| text | Indexes the file as one document, the pathname as the heading. |
| TIFF | TIFF image, one image per file. The filename is used as the headline. |
To tell waisindex the type of file to be examined, use the -t option followed by the proper type. For example, to index standard ASCII text, you could use the command:
waisindex -t text -r /usr/waisdata/*
This command indexes all the files in /usr/waisdata recursively, assuming they are all ASCII files.
When a document has been indexed, any changes in the document will not be reflected in the WAIS index unless a complete reindex is performed. Using the -a option does not update existing index entries. Instead, start the index process again. You should do this at periodic intervals as a matter of course.
Getting Fancy
You can provide some extra features for users of your freeWAIS service in a number of ways. Although this section is not exhaustive by any means, it shows you two of the easily implementable features that make a WAIS site more attractive.
To begin, suppose you want to make video, graphics, or audio available on a particular subject. Suppose, for example, your site deals with musical instruments, and you have several documents on violins. You may want to provide an audio clip of a violin
being played, a video of the making of a violin body, or a graphic image of a Stradivarius violin. To make these extra files available, you should have all the files with the same filename but different extensions. For example, if your primary document on
violins is called violins.txt, you may have the following files in the WAIS direc-tories:
| violins.TEXT | Document describing violins |
| violins.TIFF | Image of a Stradivarius |
| violins.MPEG | Video of the making of a violin body |
| violins.MIDI | MIDI file of a violin being played |
All these files should have the same root name (violins) but different types (recognized by waisindex). Then, you have to associate the multimedia files with the document file. You can do this with the following command:
waisindex -d violin -M TEXT,TIFF,MPEG,MIDI -export /usr/waisdata/violin/*
This tells waisindex that all four types of files are to be handled. When a user searches for the keyword "violin," all four types of files will be matched, and options on the browser may let them play, view, or hear the non-text components.
Another common feature is the use of synonyms to account for different methods of specifying a subject. For example, a scientist may use the keyword "feline" when a non-scientist may use "cat." You want to be able to match these two
words to the same thing. This is done through a file called SOURCE.syn, which is automatically read by the search engine when it is working. The SOURCE.syn file has the following format:
word synonym [synonym ...]
where word is the word to be used to search the databases, and synonym is the word(s) that should match it. For example, if you are dealing with domestic pets in your WAIS site, you may have the following entries in the SOURCE.syn file:
cat feline dog canine hound pooch bird parrot budgie
The synonym file can be very useful when people use different terms to refer to the same thing. An easy way to check for the need for synonyms is to set the logging option for waisindex to 10 for a while, and see what words people are using on your
site. Don't keep it on too long, though, because the logfiles can become enormous with a little traffic.
Summary
Now that WAIS is up and running on your server, you can go about the process of building your index files and letting others access your server. WAIS is quite easy to manage, and offers a good way of letting other users access your system's documents. The alternative approach, for text-based systems, is Gopher, which we examine in the next chapter.

Popular Tutorials
-
 MS Access
1109
MS Access
1109
-
 C++
1222
C++
1222
-
 HTML
584
HTML
584
-
 JavaScript
616
JavaScript
616
-
 Vbscript
873
Vbscript
873
-
 Oracle
473
Oracle
473
-
 VC++
875
VC++
875
-
 SQL
2959
SQL
2959
-
 XML
514
XML
514
-
 Java
814
Java
814
-
 Perl
455
Perl
455
-
 Linux
451
Linux
451




{kind=link}
{kind=link}
{kind=link}